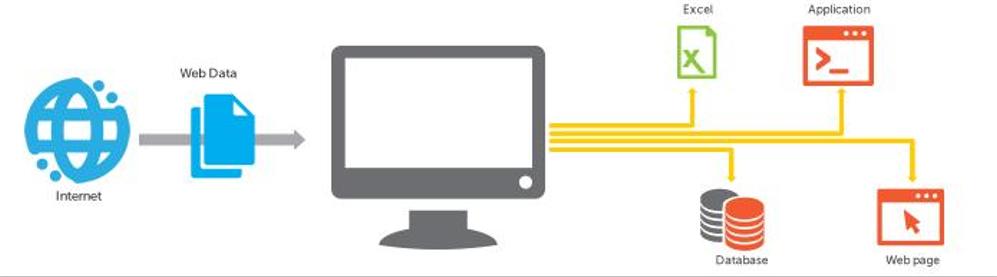
業務内容
指定していただいたURLからデータを収集します。
2階層は、指定して頂いたURLのページ内、またはURLのパラメータが規則的に1つだけ異なるページから、リンクを一つ辿った先まで対象となります。
ただし同一ドメイン内でリンク先のページ構成が変わらないことが条件となります。
CSV,TSV,xlsxのリストで納品します.
。例)iタウンページの新宿区グルメカテゴリ一覧から企業名、住所、電話番号を、詳細ページからHPのURLと営業時間を取得
https://itp.ne.jp/tokyo/13104/genre_dir/gourmet/pg/n/?sr=1&ngr=1&num=20
・nページがある限り取得します
・企業の詳細ページを辿り、HPのURL、営業時間を取得します
対応できないこと(質問はメッセージで問い合わせください)
・情報閲覧にログインが必要なサイト
・欲しい項目が固定位置でないもの
・著作権法に引っかかる項目の取得
・画像
・サイトが独自に付けたカテゴリ
・サイトが構築した文章
・欲しい項目の出力が動的なもの(javascript・flashを使用して表示する項目など)
・PDFなどHTMLではないサイト
※サイト、項目が対応可能か判断するため、先にお問い合わせください。
基本料金
実績・評価
1 件
満足
0
残念
出品者

1日前
Laravel, Django, Wordpress, Python, Scraping, SEO
-
1 件 満足0 残念
- レギュラー
- 個人
- 東京都
過去10年間、私は PHP、MySQL、Python, WordPress、Laravel 、Photoshopなどを使って幅広いWebサイトとWebアプリケーションとウェブスクレイピングを開発しました。 あなたやあなたのビジネスのために、ウェブサイトやWebアプリケーションを一から構築するチャンスを探しています。
私は不可能ではないと思う - ちょうど必要な時間、お金そして働く欲求です! あなたのアイデアを教えてください、私たちはそれについて議論し、私はあなたに将来のシステムの構造と仕事の計画を与えます。
プログラミング経験
言語:PHP(10 年間)、Python(6 年間),Java(2 年間)、C(1 年間)
プラットフォーム:Android(1 年間)
データベース:MySQL(7 年間)、SQLite(1 年間),MongoDB(3 年間)
オペレーティング·システム:Linux(7 年間), Ubuntu(8 年間),Centos(5 年間)
クラウドプラットフォーム: Digital Ocean (3 年間), AWS EC2,S3,SES (8 年間),
フレームワーク: CodeIgniter(3 年間),WordPress(10 年間), Twitter Bootstrap(5 年間),Laravel(7 年間)
Git/Gitlab/Bitbucked (10 年間)
SASS,SCSS,Google Analytics, SEO,SMM
注文時のお願い
①ウェブサイトアドレス
②カテゴリー名前
③・欲しい項目
対応可能か判断するため、先にお問い合わせをいただけると確実です。
